Text-driven 3D scene generation is widely applicable to video gaming, film industry, and metaverse applications that have a large demand for 3D scenes. However, existing text-to-3D generation methods are limited to producing 3D objects with simple geometries and dreamlike styles that lack realism. In this work, we present Text2NeRF, which is able to generate a wide range of 3D scenes with complicated geometric structures and high-fidelity textures purely from a text prompt. To this end, we adopt NeRF as the 3D representation and leverage a pre-trained text-to-image diffusion model to constrain the 3D reconstruction of the NeRF to reflect the scene description. Specifically, we employ the diffusion model to infer the text-related image as the content prior and use a monocular depth estimation method to offer the geometric prior. Both content and geometric priors are utilized to update the NeRF model. To guarantee textured and geometric consistency between different views, we introduce a progressive scene inpainting and updating strategy for novel view synthesis of the scene. Our method requires no additional training data but only a natural language description of the scene as the input. Extensive experiments demonstrate that our Text2NeRF outperforms existing methods in producing photo-realistic, multi-view consistent, and diverse 3D scenes from a variety of natural language prompts. Our code and model will be available upon acceptance.
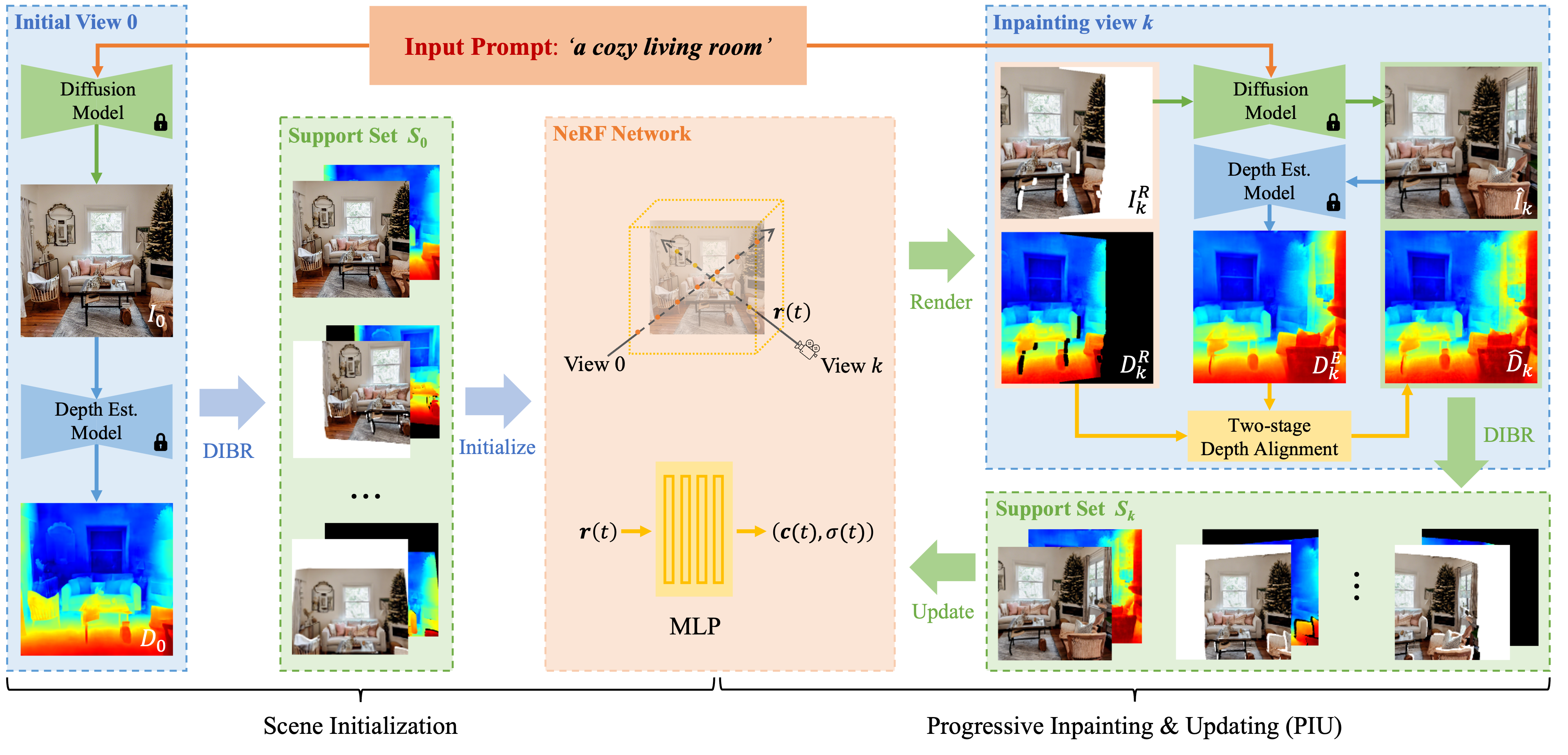
Overview of our Text2NeRF. Given an input text prompt, we infer an initial view and estimate its depth via a pre-trained diffusion model and a depth estimation model. Then we use the depth image-based rendering (DIBR) to warp the initial view and its depth map to various views to build the support set for initializing the neural radiance field (NeRF). Afterward, we design a progressive scene inpainting and updating strategy to complete missing regions consistently. During each update, we first render the initialized NeRF in a novel view to produce the image and depth with missing regions. Then, the diffusion model is adopted to generate completed image and the depth estimation model is used to predict its depth . Furthermore, a two-stage depth alignment is implemented on and to obtain aligned depth . Finally, the support set of view is added into training data to update NeRF.
a bedroom with a desk. |
a cozy living room. |
a dog playing on the lawn. |
a bonsai on the table. |
a cabin in the woods. |
a red sports car in a park. |
a locomotive at the train station. |
a deserted commercial street. |
venezia in oil painting style. |
future city in Surrealism style. |
a unicorn in a forest, CG style. |
future city in Surrealism style. |
@article{zhang2023text2nerf,
title={Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields},
author={Zhang, Jingbo and Li, Xiaoyu and Wan, Ziyu and Wang, Can and Liao, Jing},
journal={arXiv preprint arXiv:2305.11588},
year={2023}
}